 主机频道
主机频道


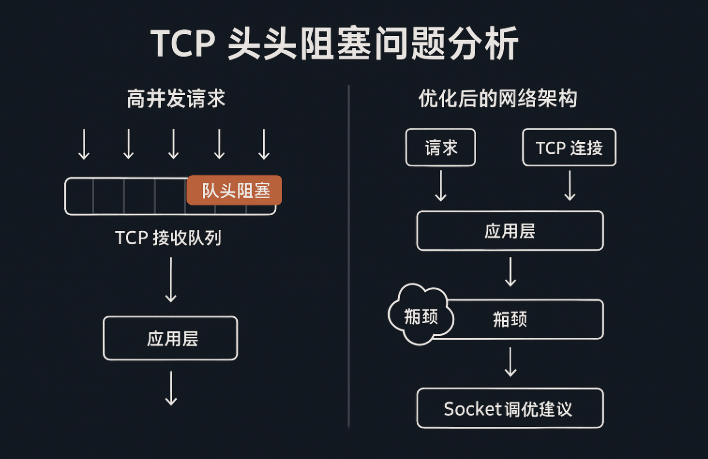
哥几个,今天聊个特玄学的话题。你有没有遇到过这种鬼故事:你服务器的CPU、内存、带宽都闲得蛋疼,监控图上一片祥和,可网站就是慢得像得了老年痴呆,用户那边疯狂投诉打不开。你查日志查到眼瞎,就是找不到任何报错。这种“一切正常,但就是慢”的灵异事件,背后很可能藏着一个老牌杀手——TCP 队头阻塞(Head-of-Line Blocking)。
这玩意儿不是什么新鲜技术,但搁在今天高并发、微服务满天飞的架构里,它就像个幽灵,平时看不见摸不着,一旦发作,能让你整个系统瘫痪得不明不白。今天,我就以一个老站长的身份,带大家把这个东西扒个底朝天。
Table of Contents
什么是 TCP 队头阻塞?别被名字糊弄了
这玩意儿听着挺唬人,说白了就是一根筋。
想象一下去超市结账,前面大妈的扫码枪坏了,她买的一车东西就卡在那儿。就算你只买了一瓶可乐,也得跟在她后面干瞪眼,整个队伍都得停下。TCP 就是这么个死脑筋,为了保证数据包“按顺序”到达,一个包卡住了,后面的所有包,管你多重要,都得给我等着。
为啥要这么死板?因为 TCP 的核心承诺就是 **可靠、有序**。它必须保证你发出去的数据,对方能原封不动、按顺序地拼起来。要是中间丢了个包,或者顺序乱了,接收方就必须停下来,等那个丢失的包重传过来,才能继续处理后面的数据。不然,传个文件缺了一块,或者网页代码乱了套,那还得了?
所以,队头阻塞的本质就是:一个数据包的问题,拖累了整条传输链路上的所有后续数据包。
高并发环境下,为什么更容易触发队头阻塞?
你可能会想,TCP 都几十岁了,怎么现在才被拎出来说事?
答案很简单:时代变了,大人。
以前的网站简单,一次请求就完事了。现在的应用,背后是复杂的微服务调用链,用户点一下按钮,可能触发几十个内部服务之间的 TCP 通信。任何一个环节的网络稍微抖一下,整个请求链路就可能被“连坐”,延迟瞬间爆炸。
下面这几个场景,简直是队头阻塞的重灾区:
1. 网络抖动 + 丢包:TCP 必须重传,延迟大增
尤其是在高峰期,哪怕网络只有 0.5% 的丢包率,TCP 的重传机制就会被激活。这机制为了稳妥,重传的等待时间是指数级增加的。第一次可能等1秒,再丢就等2秒、4秒……你这边看着只是个小小的丢包,用户那边可能早就因为加载太慢把网页关了。
最坑的是:哪怕只丢了一个小包,后面成百上千个已经到达的包也只能在缓冲区里干等着。
2. 单连接内混合请求,导致业务响应串行阻塞
这个在 HTTP/1.1 时代特别常见。浏览器为了省事,可能会在一个 TCP 连接里同时发好几个请求。结果第一个请求是个慢查询,卡住了,那后面就算是一些能秒回的请求,也得老老实实排队。反映到用户端,就是页面转了半天圈,啥也出不来。
这也是为什么 HTTP/2 搞了多路复用来缓解这个问题,而 HTTP/3 干脆抛弃 TCP,就是为了彻底根治这个毛病。
3. Nagle 算法 + 延迟确认(Delayed ACK)组合拳
玩过服务器优化的朋友,肯定对 tcp_nodelay 这个参数不陌生吧?它就是用来干掉 Nagle 算法的。Nagle 算法本意是好的,想把小的数据包攒一攒再发,省点带宽。但它和延迟确认(Delayed ACK)凑到一块,就成了灾难:服务端发了个小包,等客户端的确认(ACK);客户端收到了,寻思着等会儿有数据要回,就捎带着一起确认,结果就等上了。两边大眼瞪小眼,时间就这么浪费了。
TCP 队头阻塞带来的危害,你可能低估了
别以为这只是“慢了点”,在高并发系统里,它引起的连锁反应足以把你的服务搞垮。
☠️ 表现一:延迟暴涨 + 报警风暴
你的监控系统会突然开始尖叫,各种服务的响应时间P99值飙升,告警邮件能塞满你的邮箱。而当你焦头烂额地去排查时,却发现根源可能仅仅是一条公网线路上几个 TCP 连接被卡住了。
☠️ 表现二:业务雪崩 + 用户流失
在秒杀、抢购这种场景下,几个阻塞的连接就能拖慢成百上千个用户的请求。结果就是订单提交失败、支付超时。说得直接点,这问题就是在烧你的钱,赶你的用户。
☠️ 表现三:系统资源异常消耗
请求处理变慢,意味着每个连接占用的时间更长。这会导致应用服务器的线程池被占满,新请求进不来。接着就是内存堆积、GC压力山大,最终整个服务都可能OOM(内存溢出)挂掉。
怎么判断是 TCP 队头阻塞导致的?
这问题的排查难点在于,它太底层了,应用日志里根本不会告诉你“TCP队头阻塞了”。
但我们可以从一些蛛丝马迹里找到线索:
✅ 1. 抓包分析:看 TCP Reassembly 行为
这是最硬核的办法。用 tcpdump 或者 Wireshark 在出问题的服务器上抓包。如果你看到大量的 “TCP Retransmission” (重传) 或者 “Out-of-Order” (乱序) 包,并且某个包发出后,很久都没收到 ACK,那基本就是它了。
✅ 2. 接入应用层请求链路跟踪
像 SkyWalking、Jaeger 这类工具就派上用场了。在链路图里,你会发现某个服务调用,上游服务明明很快就响应了,但下游服务却过了很久才收到请求。中间这段“消失的时间”,很可能就是耗在 TCP 传输上了。
✅ 3. 看 SYN-ACK/ACK RTT 与数据包 RTT 差距
简单说,就是看建立连接(三次握手)快不快,和后面传数据快不快。如果 Ping 延迟或者握手延迟(RTT)只有几十毫秒,但实际业务数据传输的延迟动不动就几百毫秒甚至上秒,那说明网络本身没问题,问题出在数据传输过程中的阻塞。
✅ 4. 大量突发性连接超时或业务接口 TPS 急剧下降
这是最直观的业务表现。CPU没满、内存没爆、数据库也活得好好的,但业务的 TPS(每秒事务数)就是上不去,还伴随着大量的超时错误。这时候,就该高度怀疑是网络层出了幺蛾子。
如何缓解 TCP 队头阻塞问题?
既然 TCP 这个“死脑筋”改不了,那我们就绕开它,或者想办法让它别那么容易犯病。
✅ 1. 升级协议,能上 HTTP/3 就别继续 HTTP/1.1
这是最釜底抽薪的办法。HTTP/3 底层用的是 QUIC 协议(基于 UDP),它天生就支持多个独立的流,一个流阻塞了,完全不影响其他的。这等于把单车道高速公路改造成了多车道,从根本上解决了问题。有条件的话,赶紧安排上。
✅ 2. 关闭 Nagle 算法,开启 TCP_NODELAY
对于那些需要快速响应、小包数据频繁的场景(比如游戏、实时通信、RPC调用),别犹豫,直接关掉 Nagle 算法。牺牲一点点网络效率,换来低延迟,绝对值。
bashsetsockopt(socket_fd, IPPROTO_TCP, TCP_NODELAY, &flag, sizeof(int));
✅ 3. 限制连接单一长链路请求数,避免串行积压
别把所有鸡蛋放一个篮子里。把请求分散到多个 TCP 连接上,这样就算一个连接倒霉卡住了,影响范围也有限。比如,可以适当调大 Nginx 和后端服务之间的连接池数量,让压力分摊得更均匀。
✅ 4. 建立业务级心跳探测与请求超时控制
不能完全指望 TCP 自己。应用层也得有自己的“保险丝”。设置合理的请求超时时间,一旦超过阈值就果断放弃,并快速失败(Fail-fast),别让一个慢请求拖死整个线程。
✅ 5. 监控链路质量指标,建立异常探测策略
把网络的 RTT、丢包率、重传率这些指标都监控起来。一旦发现某条线路的质量急剧下降,就应该有自动化的策略,比如切换到备用线路,或者对这条线路上的业务进行降级处理。
实战案例分享:如何通过分析队头阻塞恢复业务
之前帮一个做SaaS的朋友看过一个问题,他们高峰期系统响应特别慢,用户疯狂投诉,但API网关监控一片正常,前端反馈的平均延迟却飙到了 800ms。最后我们是这么找到问题的:
- 在网关服务器上抓包,发现有几个连接超过 6 秒都没任何数据交互,明显卡住了。
- 通过 Prometheus 监控发现服务器的
node_network_transmit_errs_total指标有突增,说明网络发包出错了。 - 进一步分析发现,是公网链路有轻微丢包,触发了TCP重传。
- 他们为了节省连接,复用得太狠,导致一个卡住的连接影响了N多排在后面的请求。
找到病根后,对症下药:
- 调大了后端服务的连接池,让请求更分散。
- 给所有外部调用加上了严格的超时控制。
- 把内部核心的 RPC 通信升级到了 HTTP/2。
一顿操作下来,系统立马恢复了正常,延迟稳定在了 150ms 以内。
最后,说句真心话
TCP是个伟大的协议,没有它就没有今天的互联网。但说实话,它真不是为现在这种超高并发、链路错综复杂的应用场景设计的。
你可以继续依赖它的可靠性,但你必须对它的“副作用”保持警惕,尤其是那个随时可能被引爆的“队头炸弹”。
别再让一个小小的数据包,卡死你精心设计的整个业务。真正的问题,往往不是你有没有做监控,而是你是否真的理解了这些底层协议的行为模式,以及那些看起来“天经地义”的机制,是怎样在不知不觉中消耗掉你用户的耐心的。
好了,今天就聊到这。赶紧去检查下你的系统,看看有没有这个隐藏的性能杀手吧。











评论前必须登录!
注册