 主机频道
主机频道


哥几个有没有遇到过这种让人抓狂的情况?你后台的监控面板上一片绿灯,服务器状态显示“一切正常”,结果客户群、工单里炸了锅,全是“网站时断时续”、“图片刷不出来”、“丢包太严重了”的反馈。你将信将疑,自己切个流量用手机试了下,嘿,还真连不上!
这时候,八成会蹦出个词儿叫“网络抖动”。但这两个字背后到底是啥?是机房抽风了?运营商骨干网炸了?还是你这台服务器的公网IP本身就是个“残次品”?光靠你本地或者单个节点的监控,能看出个啥来?
想都别想,根本不可能!
如果你还在用“本地 Ping 一下 + 失败就告警”这种土方法来监控你的宝贝服务器,那我只能说,你永远只能跟在问题屁股后面擦,甚至连根源都摸不着。今天这篇文章,咱就来聊聊一个更靠谱的玩法——“多点 Ping 监控策略”,让你彻底搞明白怎么用数据说话,判断你的公网 IP 到底稳不稳。
Table of Contents
为什么单点 Ping 根本不够用?
咱就直说吧,你搞个监控脚本,放自己办公室电脑或者另一台服务器上,每分钟 ping 一下目标 IP,丢包三次就发邮件。这套路是不是很熟悉?
听着是那么回事,但实际上跟自欺欺人没啥两样。你想过没:
- 你的监控点和用户在同一个地方吗? 你在北京 ping 秒通,可能广州、上海的用户早就超时超成狗了。
- 去程和回程网络一样好吗? 你的 ping 包能顺利发出去,不代表数据包能顺利回来啊。
- 三大运营商一视同仁? 电信、联通、移动,这三家去你服务器走的路子可能完全不同,一家通不代表家家通。
所以说,单点 Ping 就好比你站在你家阳台上测了下 PM2.5,然后就敢说全城空气质量优良。这不扯淡嘛。
什么是“多点 Ping 策略”?
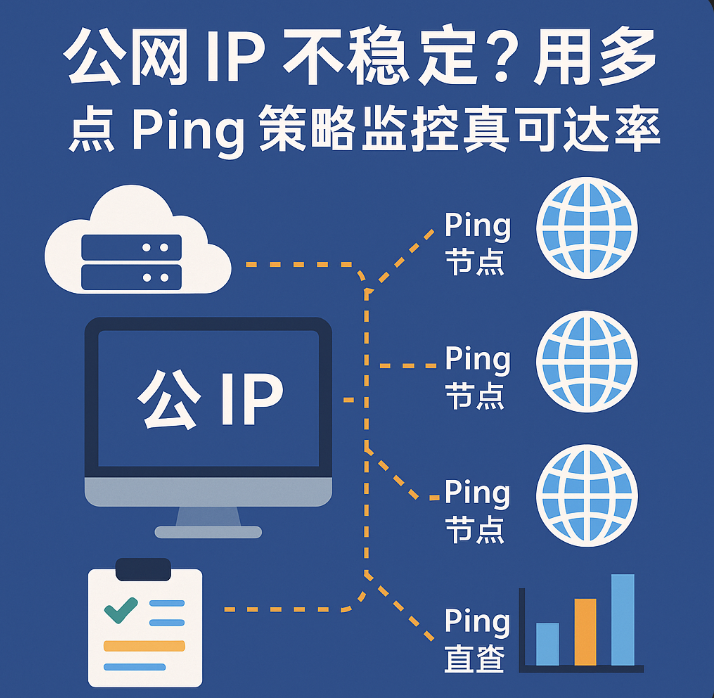
多点 Ping,说白了就是“人海战术”。从全国乃至全球,找一堆不同地理位置、不同运营商网络的“探子”(小鸡),让它们同时去 Ping 你的目标服务器,然后把所有探子回报的延迟(RTT)、丢包率、抖动(Jitter)这些情报汇总起来,你就能画出一张关于你服务器公网 IP 质量的“全球态势图”。
打个比方,这就好比:
以前你只在自家大门口装个摄像头,现在不了,你在小区门口、主干道、高速路口都安上了探头,甚至还派了几个马仔在不同路口蹲点。谁家网络到你这儿堵车,一目了然。
一套正经的多点 Ping 方案,通常得有这么几样东西:
- 分布在不同地区/运营商的多个探测节点(小鸡)。
- 足够高的探测频率,比如每 5-10 秒来一轮。
- 一个能汇总和展示所有数据的中心平台。
- 一套聪明的告警规则,而不是傻乎乎地一丢包就叫。
多点监控可以发现哪些“你本来看不到”的问题?
1. 地域性网络故障
这就是最典型的“我这儿好好的啊!”问题。比如你的服务器在阿里云北京,你也在北京,ping 起来飞快。但实际上,可能整个南方地区的移动用户访问都超时了,你却毫不知情。
只有从全国各地布点探测,你才能一眼看出:
- 是不是某个运营商的线路拉了胯。
- 是不是某个省份的访问延迟特别高。
- 是不是你的 IP 被某个区域给“特殊照顾”了(ICMP 直接被干掉)。
2. 链路拥塞或运营商限速
我个人就遇到过,一到晚上 8 点高峰期,某个电信节点的延迟就蹭蹭往上涨。这往往不是我服务器的问题,而是运营商的骨干网在那会儿太挤了。单点监控很难发现这种规律,但多点数据一拉,趋势就非常明显了。
3. 公网 IP 本身质量波动
说句实在话,不是所有云厂商给的公网 IP 质量都一样好,特别是那些共享带宽池的 EIP。在没有 BGP 线路或者精品网加持的情况下,IP 的路由路径可能会变来变去,导致网络质量也跟着飘忽不定。
多点 Ping 能把这种“IP 亚健康”状态暴露无遗,图表上会显示为:
- 延迟曲线像心电图一样剧烈波动。
- 丢包率时不时就跳一下。
- 某些地区的节点访问就是死活不通。
如何构建自己的多点 Ping 系统?
丰俭由人,我给几个路子:
方案一:手动部署多节点探测 + cron 脚本 + 数据汇总
- 去几家云服务商(比如腾讯云、阿里云、华为云)那儿买几台最便宜的轻量服务器,选不同地区。
- 在每台小鸡上写个简单的 shell 脚本,用 `cron` 定时任务每分钟执行 Ping,把结果存到日志里。
- 再用 `curl` 把日志数据定时发送到一个你自己写的接收 API。
- 用 Grafana + Prometheus 之类的组合把数据做成酷炫的仪表盘。
优点:便宜,想怎么玩就怎么玩,完全自己控制。
缺点:费事,从数据处理到图表展示都得自己搞。
方案二:使用开源平台 like SmokePing + RRDTool + Blackbox Exporter
如果你想搞得专业点,可以试试 SmokePing。这玩意儿是很多老网工的最爱,专门用来画网络质量图的,能非常直观地展示延迟分布和丢包情况。
或者用现在更流行的 Prometheus + Blackbox Exporter 组合拳,监控能力更全面。
方案三:采用商业方案(推荐中小企业)
如果你是企业用户,或者就是懒得折腾,直接花钱买服务最省心:
- CloudPing
- DNSPerf / CDNPerf
- 各大云厂商自带的拨测服务,比如阿里云的云拨测、腾讯云的可用性监控。
这些服务节点遍布全球,点几下鼠标就能配置好,出了问题直接给你发告警,省时省力。
如何设计告警策略才不会“假阳性”或“假阴性”?
这是个关键问题,不然半夜能被告警短信烦死。
一个 ping 不通就告警?那纯属自己给自己找事。
聪明的告警策略应该是这样的:
- 按比例告警:我有 10 个探测点,只有当超过 3 个点同时挂了,才算个事儿,才需要告警。
- 按时间窗口告警:不能抖一下就叫。得是连续 3 分钟都处于异常状态,这才确认是真故障。
- 按区域分组告警:比如南方的 3 个节点全挂了,但北方的都好好的,告警信息里就应该明确指出“华南区网络异常”,这样排查起来方向才明确。
更高级的玩法,还可以让系统学习历史数据,比如某个 IP 每天凌晨 3 点都会固定抖动 1 分钟,那就把这个时段的告警敏感度调低,避免无效骚扰。
结合 TCP 和应用层监控,做全链路感知
要记住,Ping 只是万里长征第一步,它只告诉你 ICMP 这条小路通不通。但你的业务跑在 TCP 上,甚至 HTTP 上。
所以,更进一步的监控应该包括:
- 用 `curl` 或 `wget` 从探测节点去访问你的网站,看看 HTTP 状态码是不是 200。
- 做 TCP 端口探测,看看 80、443 这类关键端口能不能建立连接。
- 出问题时,用 Traceroute 分析一下路由路径,看看是在哪一跳出了问题。
- 终极玩法:在探测节点上跑个小脚本,模拟真实用户操作,比如登录、查询,看整个业务流程是否通畅。
只有把这些组合起来,你才能从“服务器活着”升级到“我的服务真的可用”。
推荐工具组合
多点 Ping 的价值在于什么?
- 它不是让你搞一堆花里胡哨的数据,而是实打实地帮你在用户投诉前发现问题。
- 它不只是画几个图给你看,而是帮你建立起一套判断网络健康的基准线。
- 它不是要取代你现有的监控,而是把你视野里最大的那个盲区给补上。
现在这个时代,业务恨不得部署到全球,云原生架构越来越复杂,你需要的早就不再是单个的监控点了,而是一套能感知全局的“雷达系统”。
说到底,如果你连自己的公网 IP 啥时候抽风都不知道,那等着你的,就只有用户的流失、业务的中断和永远背不完的锅。
结语:
别再用“我本地 Ping 了一下,是好的”来安慰自己了,也别总等到用户找上门才手忙脚乱地排查问题。
从今天起,花点时间搞个自己的多点 Ping 系统吧。哪怕只是最简单的两三个节点,只要能真实反映出不同地区、不同网络的连接质量差异,你就已经走在了正确的路上。
记住,谁能先掌握网络的全局视角,谁就能在事故发生前把它扼杀在摇篮里,赢得最宝贵的稳定和口碑。










评论前必须登录!
注册